Haar特征
图像特征提取的三种方式:HOG特征,LBP特征,Haar特征。Haar特征:也叫Haar-like特征、哈尔特征,是图像特征提取的一种方法。
Haar特征分为三类:边缘特征、线性特征、特定方向特征(中心特征和对角线特征),组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar特征值反映了图像的灰度变化情况。例如:脸部的一些特征能由矩形特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。但矩形特征只对一些简单的图形结构,如边缘、线段较敏感,所以只能描述特定走向(水平、垂直、对角)的结构。
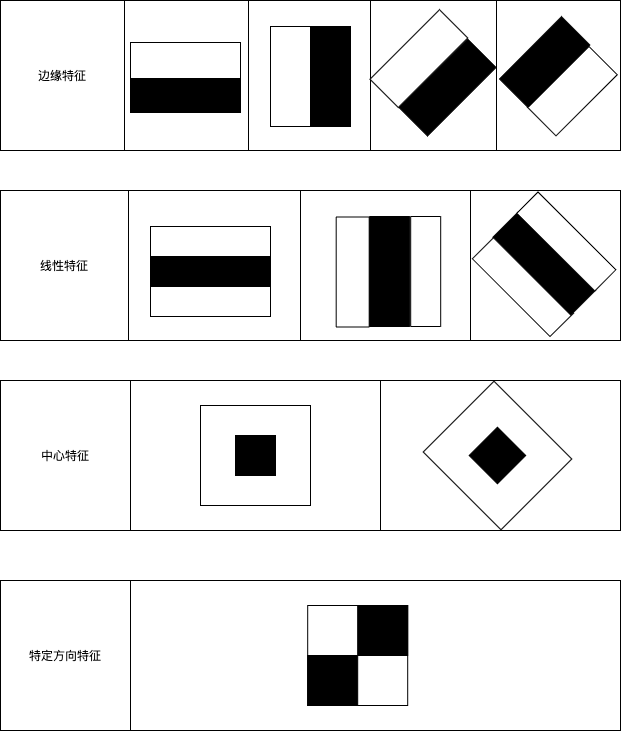
常用的矩形特征有三种:两矩形特征、三矩形特征、四矩形特征:如边缘特征是两矩形特征,线性特征是三矩形特征,特定方向特征是四矩形特征。如果特征模版的黑白矩形按宽高比来分段的话,那具体的比例如下表: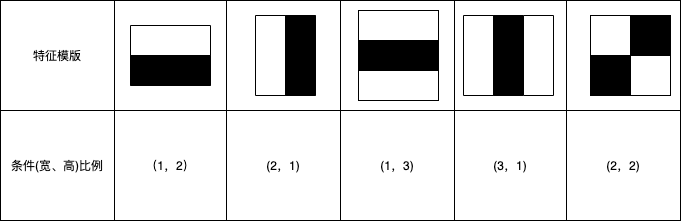
Haar特征个数计算
通过改变特征模板的大小和位置,可在图像子窗口中穷举出大量的特征。上图的特征模板称为“特征原型”;特征原型在图像子窗口中扩展(平移伸缩)得到的特征称为“矩形特征”;矩形特征的值称为“特征值”。
对于 m×m 子窗口,我们只需要确定了矩形左上顶点A(x1,y1)和右下顶点B(x2,y2) ,即可以确定一个矩形;如果这个矩形还必须满足下面两个条件(称为(s, t)条件,满足(s, t)条件的矩形称为条件矩形):
1) x 方向边长必须能被自然数s 整除(能均等分成s 段);
2) y 方向边长必须能被自然数t 整除(能均等分成t 段);
则 , 这个矩形的最小尺寸为s×t 或t×s, 最大尺寸为[m/s]·s×[m/t]·t 或[m/t]·t×[m/s]·s;其中[ ]为取整运算符。

这种计算方式可能不太直观,那用下面的列表方式看一下就很清楚了,我们知道特征原型在图像窗口中根据平移伸缩得到矩形特征。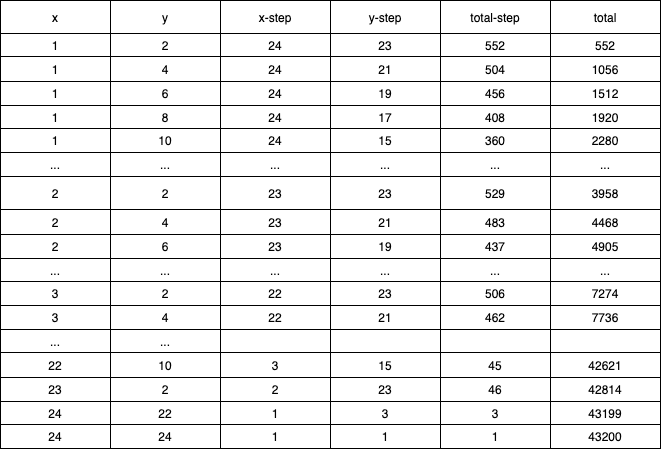
综上,可以计算出24x24的特征总数为 43200+27600+43200+27600+20736=162336。所以五种可能的类型就产生了16万以上的特征数量,同时也就是16万以上的特征值,这个是一个非常大数字了。上图通过代码进行计算就是如下:
计算某一种特征的特征数量;
1 | totalCount(24,24,2,2); |
特征数量的计算函数:
1 | private int totalCount(int width,int height,int scaleWidth,int scaleHeight){ |
实现类似python的range函数:
1 | public class Range implements Iterable<Integer> { |
积分图
积分图就是只遍历一次图像就可以求出图像中所有区域像素和的快速算法,大大的提高了图像特征值计算的效率。
积分图主要的思想是将图像从起点开始到各个点所形成的矩形区域像素之和作为一个数组的元素保存在内存中,当要计算某个区域的像素和时可以直接索引数组的元素,不用重新计算这个区域的像素和,从而加快了计算(这有个相应的称呼,叫做动态规划算法)。积分图能够在多种尺度下,使用相同的时间(常数时间)来计算不同的特征,因此大大提高了检测速度。
积分图是一种能够描述全局信息的矩阵表示方法。积分图的构造方式是位置(𝑖,𝑗)处的值𝑖𝑖(𝑖,𝑗)是原图像(𝑖,𝑗)左上角方向所有像素𝑓(𝑘,𝑙)的和:
𝑖𝑖(𝑖,𝑗)=∑𝑘≤𝑖,𝑙≤𝑗𝑓(𝑘,𝑙)
积分图构建算法:
1、用𝑠(𝑖,𝑗)表示行方向的累加和,初始化𝑠(𝑖,−1)=0;
2、使用𝑖𝑖(𝑖,𝑗)表示一个积分图像,初始化𝑖𝑖(−1,𝑖)=0;
3、逐行扫描图像,递归计算每个像素(𝑖,𝑗)行方向的累加和𝑠(𝑖,𝑗)和积分图像𝑖𝑖(𝑖,𝑗)的值:
𝑠(𝑖,𝑗)=𝑠(𝑖,𝑗−1)+𝑓(𝑖,𝑗)
𝑖𝑖(𝑖,𝑗)=𝑖𝑖(𝑖−1,𝑗)+𝑠(𝑖,𝑗)
4、扫描图像一遍,当到达图像右下角像素时,积分图像𝑖𝑖就构建好了。
积分图构造好之后,图像中任何矩阵区域像素累加和都可以通过简单运算得到如图所示: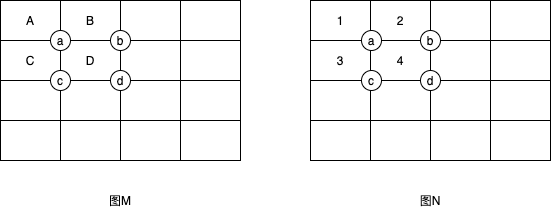
在图M中,设D的四个顶点分别为a,b,c,d,则D的像素可以表示为:
𝐷𝑠𝑢𝑚=𝑖𝑖(a)+𝑖𝑖(d)−(𝑖𝑖(b)+𝑖𝑖(c))
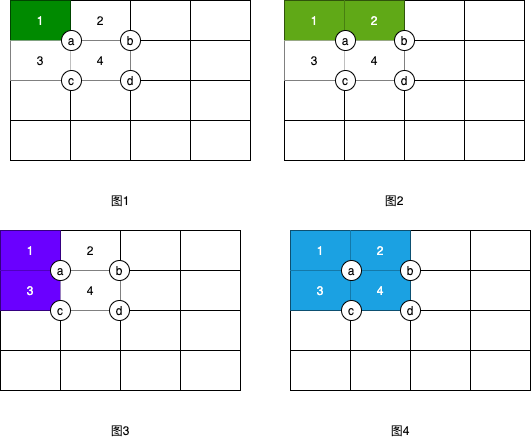
看起来还是很抽象:那我们看图N,我们分别假设ABCD四个矩形的像素为1,2,3,4.
所以
a点像素值:1
b点像素值:1+2=3
c点像素值:1+3=4
d点像素值:1+2+3+4=10
验证下上面公式:1+10-(3+4)=4,所以矩形D=4是正确的。还是不直观,那我们用图表验证下:
可以看到,(𝑖𝑖(b)+𝑖𝑖(c))后,有一部分重合的区域,即A,所以需减掉,最后还需要将当前坐标d的像素值D包含进来。
(𝑖𝑖(b)+𝑖𝑖(c))-A+D = 𝑖𝑖(d) ==> D= 𝑖𝑖(d) + A - (𝑖𝑖(b)+𝑖𝑖(c)) 由于A=𝑖𝑖(a)所以可以推出
𝐷𝑠𝑢𝑚=𝑖𝑖(a)+𝑖𝑖(d)−(𝑖𝑖(b)+𝑖𝑖(c))
所以无论矩形的尺寸大小,只需查找积分图像4次就可以求得任意矩形内像素值的和。
计算特征值
上面已经知道,一个区域的像素值的和,可以由该区域的端点的积分图来计算。由前面特征模板的特征值的定义可以推出,矩形特征的特征值可以由特征端点的积分图计算出来。以A矩形特征为例,如下图,使用积分图计算其特征值:
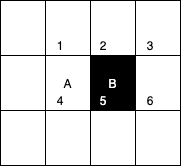
该矩形特征的特征值,由定义,为区域A的像素值减去区域B的像素值。
区域A的像素值:
𝑖𝑖(5)+𝑖𝑖(1)−𝑖𝑖(2)−𝑖𝑖(4)
区域B的像素值:
𝑖𝑖(6)+𝑖𝑖(2)−𝑖𝑖(5)−𝑖𝑖(3)
所以:该矩形特征的特征值
𝑖𝑖(5)+𝑖𝑖(1)−𝑖𝑖(2)−𝑖𝑖(4)−[𝑖𝑖(6)+𝑖𝑖(2)−𝑖𝑖(5)−𝑖𝑖(3)]
=[𝑖𝑖(5)−𝑖𝑖(4)]+[𝑖𝑖(3)−𝑖𝑖(2)]−[𝑖𝑖(2)−𝑖𝑖(1)]−[𝑖𝑖(6)−𝑖𝑖(5)]
所以,矩形特征的特征值,只与特征矩形的端点的积分图有关,而与图像的坐标无关。通过计算特征矩形的端点的积分图,再进行简单的加减运算,就可以得到特征值,正因为如此,特征的计算速度大大提高,也提高了目标的检测速度。
然后看一个复杂一点的积分图示例如下:
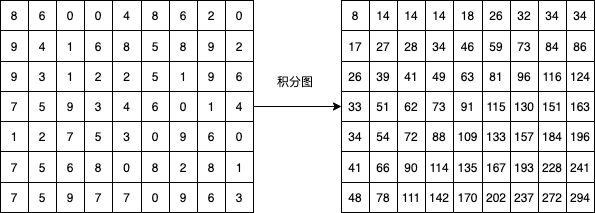

然后计算一下颜色区域的特征值:
根据积分图公式:
特征A:2
总的像素值(有颜色区域的像素值)= 130+8-32-33 = 73
白色区域的像素值 = 91+14-18-62 = 25
特征值:3白-总 = 325 -23 = 2
左侧黑色区域的像素值 = 62+8-14-33 = 23
右侧黑色区域的像素值 = 130+18-32-91 = 25
特征值:2白-黑 = 225-23+25 = 2
通过同样计算方式:特征B:-2
这个时候我们会发现,跟之前提到的特征值定义,不符合了,之前说过特征值为白色矩形像素和减去黑色矩形像素和,按此计算,应该是-23和23.那么问题在哪里?看上述我们计算发现,我们在计算特征值的时候都乘以了一个变量,3和2,那为啥要乘以两个变量呢?按照OpenCV代码,(Haar特征值=整个Haar区域内像素和×权重 + 黑色区域内像素和×权重)Haar特征值=白色区域内图像像素和 x 权重 - 黑色区域内图像像素和 x 权重,那变量3和2其实就是权重。这也就是其他文章中提到的所谓“白色区域像素和减去黑色区域像素和”,只不过是加权相减而已(在XML文件中,每一个Haar特征都被保存在2~3个形如
1 |
|
例如上Haar特征应该表示为<7 1 2 7 -1>和<8 1 1 7 2>,原则上-1权重代表的是黑色矩形。
为什么要设置这种加权相减,而不是直接相减?请仔细观察上图中的特征,不难发现x3、y3、point特征黑白面积不相等,而其他特征黑白面积相等。设置权值就是为了抵消面积不等带来的影响,保证所有Haar特征的特征值在“灰度分布绝对均匀的图像”中为0。
级联分类器
XML
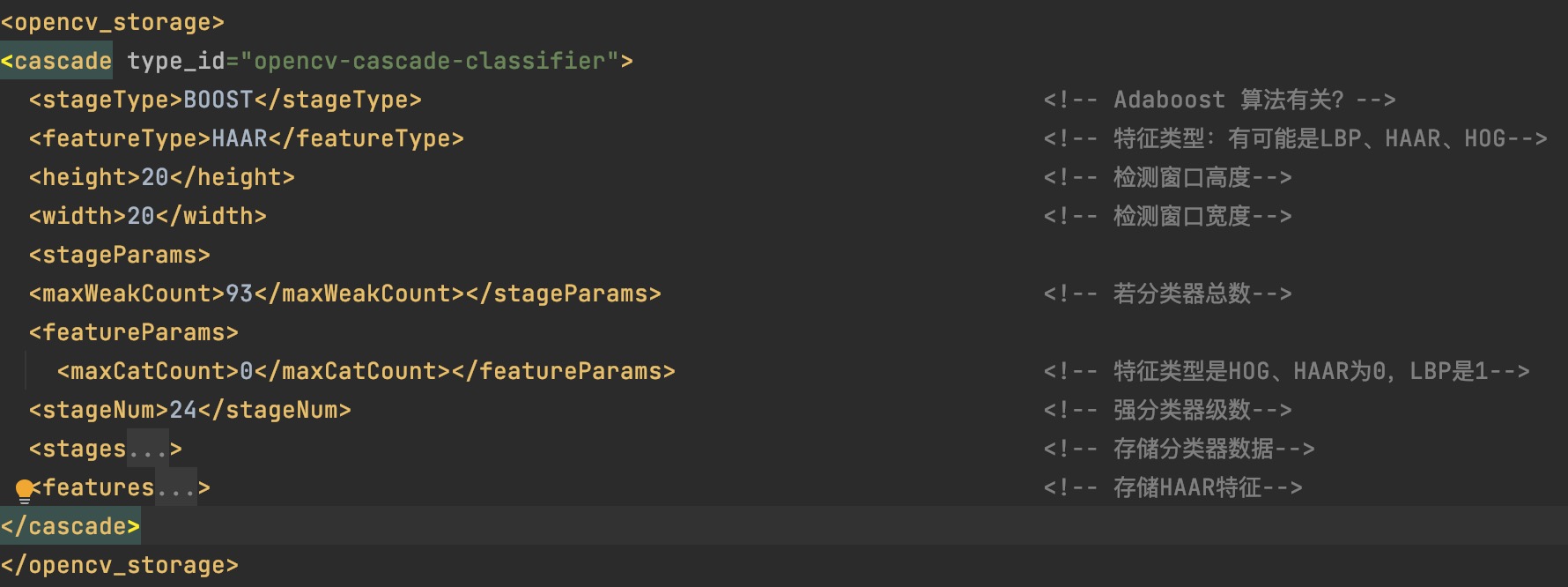
分类器

1 | <internalNodes>0 1 2 5.2434601821005344e-04 -1 -2 3 4.4573000632226467e-03</internalNodes> |
internalNodes:
0 、1,-1 、-2,则用于控制弱分类器树的形状;
5.2434601821005344e-04,弱分类器阈值t1;
4.4573000632226467e-03,弱分类器阈值t2;
2 、3 代表2个Haar特征位置;
leafValues:返回值。
其中标签中的3个浮点数,对应下图的三个value值,由左向右依次是rightValue2、leftValue和rightValue1;
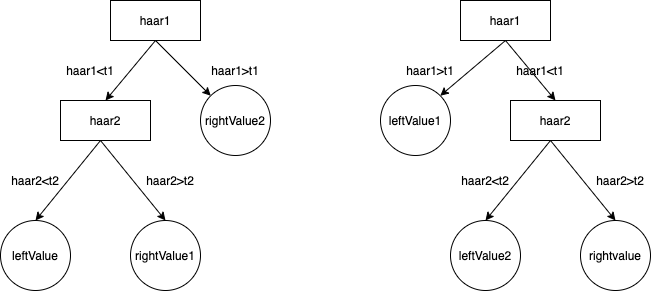
1.计算第一个Haar特征的特征值haar1,与第一个弱分类器阈值t1对比,当haar1<t1时,进入步骤2;当haar1>t1时候,该弱分类器输出rightValue2并结束。
2.计算第二个Haar特征值haar2,与第二个弱分类器阈值t2对比,当haar2<t2时候输出leftValue;当haar2>t2时输出rightValue1。
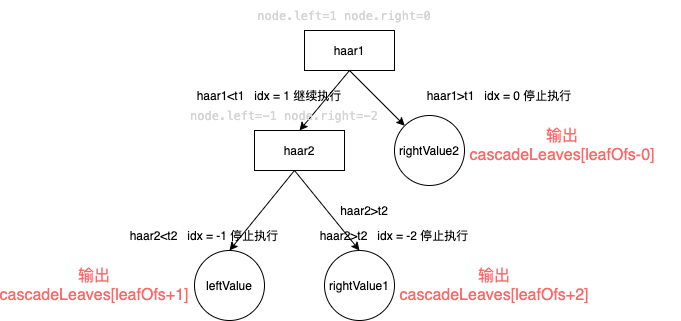
1、0和-1、-2则用于控制弱分类器树的形状。在运行时,OpenCV会把1赋值给当前的node.left,并把0赋值给node.right(请注意do-while代码中的条件,只有idx<=0时才停止循环,参考图3应该可以理解这4个整数的含义)。如此,OpenCV通过这些巧妙的数值和结构,控制了整个分类器的运行。可以看到,每个弱分类器内部都是类似于这种树状的“串联”结构,所以我称其为“串联组成的的弱分类器”。
强分类器结构
在opencv中,强分类器是有多个弱分类器“并列”构成,即强分类器中的弱分类器是两两相互独立的。在目标检测时,每个弱分类器独立运行并输出cascadeLeaves[leafOfs-idx]值,然后把当前强分类器中每个弱分类器的输出值相加,即:
1 | sum += cascadeLeaves[leafOfs - idx]; |
之后与本级强分类器的stageThreshold阈值对比,当且仅当结果sum>stageThreshold时,认为当前检测窗口通过了该级强分类器。当前检测窗口通过所有强分类器时,才被认为是一个检测目标。可以看出,强分类器与弱分类器结构不同,是一种类似于“并联”的结构,我称其为“并联组成的强分类器”。
检测流程
Haar级联分类器: 通过分析对比相邻图像区域来判断给定图像或者图像区域与已知对象是否匹配。
可以将多个Haar级联分类器组合起来,每个分类器负责匹配一个特征区域(比如眼睛),然后进行总体识别。
也可以一个分类器进行整体区域识别(比如人脸),其他分类器可识别小的部分(比如眼睛)等。
Haar特征具有尺度不变性,就是说它在尺度变换上具有鲁棒性。
Opencv提供了尺度不变的Haar级联分类器和跟踪器。但其并不具有旋转不变性。举个例子,opencv提供的Haar级联分类器并不认为侧脸和正脸一样,倒置的人脸和正脸一样。
训练过程: 输入图像->图像预处理->提取特征->训练分类器(二分类)->得到训练好的模型 ;
测试过程:输入图像->图像预处理->提取特征->导入模型->二分类(是不是所要检测的物体);
参考资料
Cascade Classifier Training
人脸检测之Haar分类器
积分图及其应用
人脸Haar特征快速检测及其特征计算
Haar特征与积分图
Haar特征详细介绍
级联分类器结构与XML文件含义
adaboost+haar目标检测技术
Ursprünglicher Link: http://nunu03.github.io/2021/04/27/人脸检测之Haar特征介绍/
Copyright-Erklärung: 转载请注明出处.